
Recently, Caktus has been using Tailscale to manage VPN connections between Android tablets and a central server. We wanted to report on the devices connected to the network using the Tailscale API. While we could use tools like Celery to fetch data from the API and load it into a database—given its widespread use in the Django ecosystem—we also wanted to explore other options.
Dagster is an orchestration tool designed to manage data pipelines. Being Python-based, Dagster can complement a Django web application by providing a method to manage data pipelines that operate independently from the web application itself.
You might use an orchestrator to:
- Fetch data from an API on a regular schedule
- Transform the data using Pandas or dbt
- Periodically run reports on the data
- Load the data into a database or data warehouse
Initially, I wasn't entirely clear on how an orchestrator fits into a data pipeline or the Extract, Transform, Load (ETL) process. While it's true that you could simply write a script to fetch data from an API and load it into a database, the advantage of using an orchestrator is that it provides a consistent way to manage and execute data pipelines. Additionally, it offers observability into the execution of these pipelines, which is beneficial for debugging and monitoring in production environments.
In this blog post, we will guide you through the process of creating a new Dagster project and developing an asset that retrieves the list of devices from the Tailscale API so that we can generate reports on the devices connected to our network.
Creating a new Dagster project
We'll start with a scaffold project by following the official Creating a new Dagster project instructions in the Dagster documentation.
pip install dagster
dagster project scaffold --name dagster-tailscale-devices
Install the required dependencies:
cd dagster-tailscale-devices
pip install -e ".[dev]"
Start the development environment:
dagster dev
You now have a new Dagster project ready to go.
Create a Tailscale API access token
To access the Tailscale API, you'll need to create an access token. You can do this by visiting the Tailscale admin console and creating a new API key.
Export the access token and your tailnet as environment variables:
export TAILSCALE_API_KEY="your-api-key"
export TAILSCALE_TAILNET="your-tailnet"
Create the Dagster asset
Next we'll create a new Dagster asset that fetches the list of devices from the Tailscale API:
import os
import requests
import dagster as dg
@dg.asset
def tailscale_devices(context: dg.AssetExecutionContext) -> dict:
headers = {
"Authorization": f"Bearer {os.getenv('TAILSCALE_API_KEY')}",
}
tailnet = os.getenv("TAILSCALE_TAILNET")
url = f"https://api.tailscale.com/api/v2/tailnet/{tailnet}/devices"
response = requests.get(url, headers=headers)
response.raise_for_status()
devices = response.json()
context.log.info(f"Downloaded {len(devices['devices'])} devices from Tailscale")
context.add_output_metadata({"devices_preview": devices["devices"][:2]})
return devices
This asset fetches the list of devices from the Tailscale API and logs the number of devices downloaded. It also adds a preview of the devices to the asset metadata, which can be viewed in the Dagster asset run details.
Now visit http://localhost:3000/assets/tailscale_devices and click the Materialize button to fetch the devices. You should see the number of devices downloaded and a preview of the first two devices.
Load the devices into a PostgreSQL database
We'll use Pandas and Psycopg to load the devices into a PostgreSQL, so we add these dependencies to the project:
diff --git a/pyproject.toml b/pyproject.toml
index 0ae6d62..1a25b08 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -8,6 +8,7 @@ dependencies = [
"dagster",
"dagster-cloud",
+ "dagster-pandas",
+ "psycopg",
]
Install the new dependencies:
pip install -e ".[dev]"
And configure an environment variable to connect to the PostgreSQL database:
export DATABASE_URL="postgresql://user:password@localhost:5432/dbname"
To load the devices into a PostgreSQL database, we'll create a new
Dagster asset that depends on the tailscale_devices asset and writes
the devices to a table.
import datetime as dt
import os
import dagster as dg
import pandas as pd
import sqlalchemy
import sqlalchemy.types as types
@dg.asset
def tailscale_device_table(
context: dg.AssetExecutionContext,
tailscale_devices: dict,
) -> pd.DataFrame:
df = pd.DataFrame(tailscale_devices["devices"])
# Add preview of the DataFrame to the context
context.add_output_metadata(
{"df_preview": dg.MetadataValue.md(df.head().to_markdown())}
)
# Add a column with the time the data was synced
df["synced_at"] = dt.datetime.now(tz=dt.UTC)
# Convert date-related columns to datetime
df["created"] = pd.to_datetime(df["created"], utc=True)
df["expires"] = pd.to_datetime(df["expires"], utc=True, errors="coerce")
df["last_seen"] = pd.to_datetime(df["last_seen"], utc=True)
# Append the DataFrame to the database
engine = sqlalchemy.create_engine(url=os.getenv("DATABASE_URL"))
df.to_sql(
name="tailscale_devices",
con=engine,
if_exists="append",
index=False,
dtype={
"addresses": types.ARRAY(types.TEXT),
"tags": types.ARRAY(types.TEXT),
},
)
return df
This asset converts the devices to a DataFrame, adds a preview of the
DataFrame to the asset metadata, and appends the DataFrame to a
PostgreSQL table named tailscale_devices.
Now visit http://localhost:3000/assets/tailscale_device_table and click the Materialize button to load the devices into the PostgreSQL database. You should see a preview of the first five devices in the asset metadata.
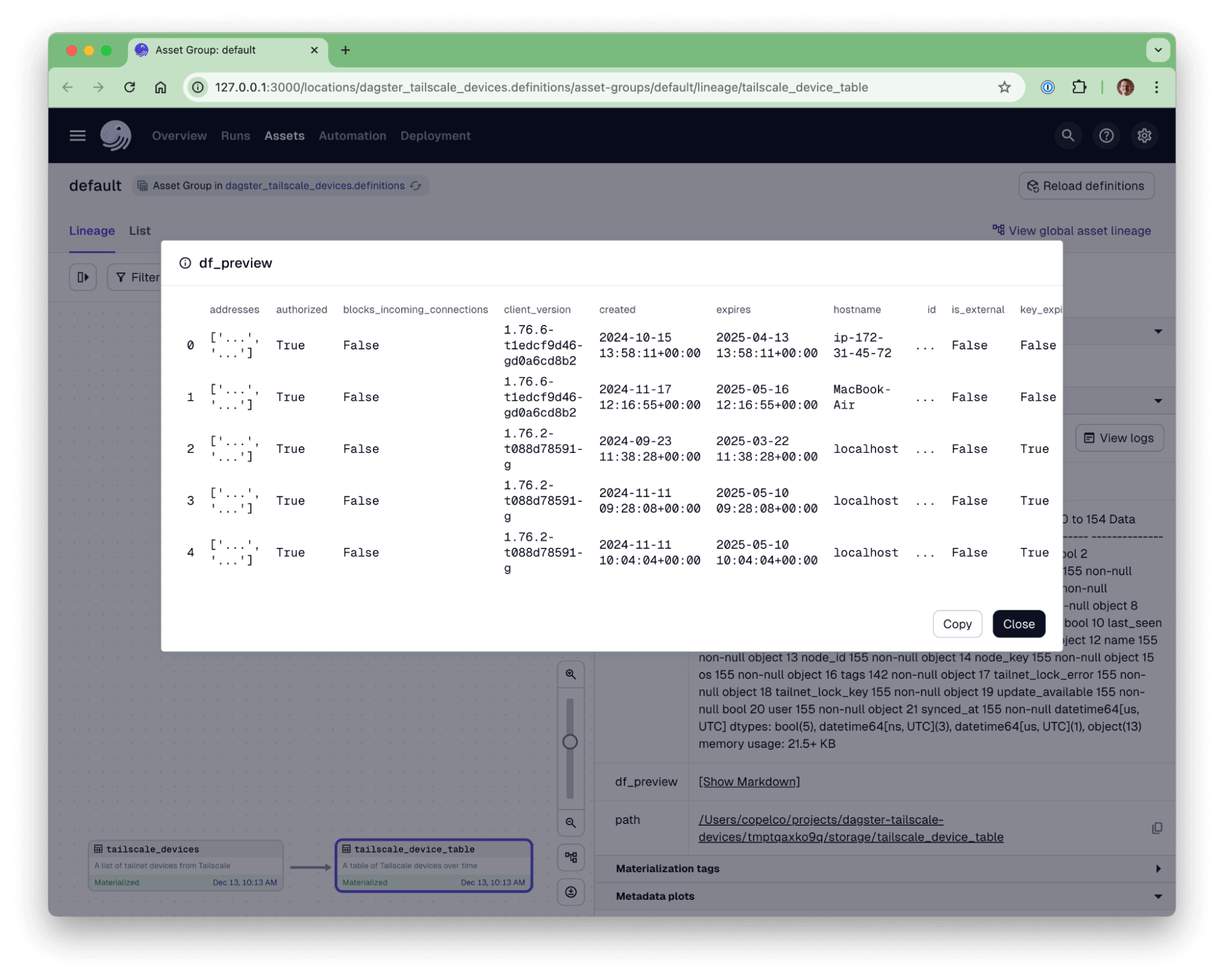
You should see a table in your PostgreSQL database with the devices from the Tailscale API:
tailscale_devices=# \d tailscale_devices
Table "public.tailscale_devices"
Column | Type | Collation | Nullable | Default
-----------------------------+--------------------------+-----------+----------+---------
addresses | text[] | | |
authorized | boolean | | |
blocks_incoming_connections | boolean | | |
client_version | text | | |
created | timestamp with time zone | | |
expires | timestamp with time zone | | |
hostname | text | | |
id | text | | |
is_external | boolean | | |
key_expiry_disabled | boolean | | |
last_seen | timestamp with time zone | | |
machine_key | text | | |
name | text | | |
node_id | text | | |
node_key | text | | |
os | text | | |
tags | text[] | | |
tailnet_lock_error | text | | |
tailnet_lock_key | text | | |
update_available | boolean | | |
user | text | | |
synced_at | timestamp with time zone | | |
Conclusion
This is a basic example, but I appreciate the simplicity of the Dagster pipeline creation process. You can create data pipelines using straightforward Python functions, and the Dagster UI allows you to visualize the assets and their dependencies. Next, I plan to explore Dagster's capabilities for unit testing and integration testing and scheduling periodic asset runs.
There are many options available in this space, including Airflow, Prefect, and Airbyte. Each of these tools has its own strengths and weaknesses, so I recommend exploring them to find the one that best fits your needs.